
Alternative Data Weekly #141

Thanks for being here!
Announcements:
If you have interest in sponsoring this weekly email & reaching this wonderful audience let me know.
Theme that emerged in this week’s email is … AI is improving rapidly … but reliant on good data and domain knowledge to put the tools to good use.
QUOTES
“…generative AI is likely to have the biggest impact on knowledge work, particularly activities involving decision making and collaboration, which previously had the lowest potential for automation” - McKinsey’s The economic potential of generative AI: The next productivity frontier
“The business must fund data gathering, or this doesn’t work. The data being gathered must have a well-defined connection to a business system, or this doesn’t work.” - Vin Vashishta
News Articles
Podcasts
Cool Charts
New Offerings …A word from our sponsor
Final Thoughts (Using Social)

#1 – Matt Ober’s Exclusive Data - Building a Moat June 2023.
My Take: “If you don’t own the data you have to be creative”. I like to think of this in terms of the data owner. There is an inflection point where you spread your data so thin it becomes less valuable (alpha decay), but then it magically becomes “table stakes” where everyone needs to have it because everyone else has it. In between those two is a tricky place.
#2 – McKinsey’s The economic potential of generative AI: The next productivity frontier. June 2023.
My Take: I enjoy these high-level thought pieces. No doubt generative AI will add to our productivity in time. What is amazing to me is the pace of progress. The article cites Anthropic’s generative AI, which was able to process 100,000 tokens of text per minute in May ‘23 vs just 9,000 in March ‘23 (just 2 months earlier). That is Moore’s Law on steroids. The pace of adoption for those basic tasks like coding help, research assistance, or writing editors … is happening so quickly because it is so amazingly easy.
#3 – Vin Vashishta’s LLMs And Causal Discovery: A Product And Data First Approach. June 2023.
My Take: I really like how the author frames the goal…business won’t fund a project gathering data for causal discovery … but a business will fund resources to better understand supply chain. Again, we find ourselves talking about the importance of domain knowledge. For businesses, don’t frame your goal as the interesting technical challenge that may draw the best technical talent, but rather frame the goal in terms of how the business will get better with the knowledge you will gain.
“No experiment can produce data that leads to a causal model without a basic understanding of what is known and unknown about the system.” (i.e. get that domain knowledge).
BONUS: Jason Derise’s The Paradox of Finding Surprising Insights in Alternative Data. June 2023. “Good institutional investors know that "All models are wrong, but some are useful”, to paraphrase the quote attributed to George Box.”
What else I am reading:
All Change Snowflake Summit summary from David Jayatillake. June 2023.
Inflection AI announces $1.3 billion of funding led by current investors, Microsoft, and NVIDIA. June 2023.
Elementl’s CEO Pete Hunt authored The Dagster Master Plan. June 2023.
Jason Derise’s (yes, another Jason Derise article … these are good) 8 point approach to evaluating data partners. June 2023.

Source: Richie Cotton of DataFramed interviews Seth Partnow about how data is being used in the NBA.
My Take: This interview drew my attention as a sports fan. Three areas data can impact sports: 1- sports science (injury prevention), 2- player selection, 3- game analysis. This interview focused on game analysis. MLB has been the leader in sports analytics, and while it is more difficult to apply data to dynamic sports like basketball or hockey (my favorite), there is significant value to be found using data analytics to improve your team. Just the act of data collection is difficult in dynamic sports. They currently collect ~900,000 data points per game. This is going to 10m+ data points per game. Wow! There is a huge attribution problem. For example, if someone misses a shot is it attributed to good defense or did they just miss the shot. Related but unrelated is Adam Braff’s Footy Moneyball: great expectations (soccer & data).
Some history (I love this kind of historical context):
up through 1996 only box score data (hundreds of data point per game)
starting ‘96 data quality improved and NBA started doing detailed play-by-play. Where shots taken, who was on floor at the time, etc. unlocked another level of data (hundreds of thousands of data points per game)
2013-14 player tracking data (player identified 25x per second). Can much more effectively understand quality of shot taken (tens of millions of data points per game allowing the ability to “watch” games at scale)_
Universe of “players that matter” is considerably smaller for NBA than MLB. Basically, in basketball, 1-2 players can change the course of a franchise, while other sports like MLB, NFL, etc require more of a team to succeed.
Highlights:
Minute 01:45 – interview starts; what problems are basketball teams trying to solve? Business side vs sport side (Seth was on sport side)
Minute 04:00 – which teams make good use of data? How integrated in the process is data? ESPN has rankings of teams making the best use of data
Minute 05:40 – are data teams in house or external?
Minute 08:00 – Mid-Range Theory book & theme that it is hard to figure out attribution of what players added the most value during a game
Minute 11:45 – standard statistics (old & new). Scoring volume and frequency. Level of shot difficulty.
Minute 15:00 – “3&D” players (low volume/high efficiency)
Minute 16:00 – three levels of data at NBA level of play
Minute 20:30 – how to make the best use of all this new data being collected?
Minute 23:00 – how is the data changing the game? Size vs skill; rise of 3-pointers taken
Minute 31:00 – what’s next? Analysis of defense is challenging. Lots of counterfactuals. Becomes very complex. Attribution problem.
Minute 33:30 – discussion of careers in sports analytics
Minute 43:30 – discussion of playoffs (this was recorded during 2023 playoffs).
…Next one….
Source 2: The Data Exchange Podcast interviews Amin Ahmad of Vectara.
My Take: This is one of the more technical data podcasts I’ve attempted to summarize. Bottom line, there has been tremendous progress in the past few years in the realm of search & information retrieval. Three takeaways for me: 1- seeing LLMs become deployable by organizations (using internal data), 2 - Strong multi-modal retrievals (text, video, audio, etc), 3 - hardware getting better allowing for fewer latency issues
Highlights:
Minute 01:00 – interview starts
Minute 01:30 – period up to October 2022 (right before release of ChatGPT)
Minute 03:30 – key building blocks in place at various times that allowed for the progress
Minute 07:00 – how to get ranked results
Minute 09:30 – Amin starting vectara in 2020 for “Neural information retrieval”
Minute 14:45 – the challenge and importance of scale
Minute 18:15 – first instances of multimodal search
Minute 20:00 – pipeline for neural information retrieval. This has changed a lot and continues to change
Minute 26:00 – user interface expectations have changed with ChatGPT
Minute 27:15 – retrieval augmented system; respond in relevant way. Training system on companies internal data.
Minute 31:30 – APIs today but within 6-12 months it will be more feasible to deploy LLMs and never have data leave their premises. Smaller, more effective models do well. This will allow customized models for organizations.
Minute 34:30 – stitching results/answers together from different modalities( video, text, etc) is tough and getting better with neural networks
Minute 41:00 – fully automated decision making … we aren’t there yet, but attractive solution and could get “dangerous”

Source: Bigeye’s 19-page State of Data Quality Report. June 2023.
Summary:
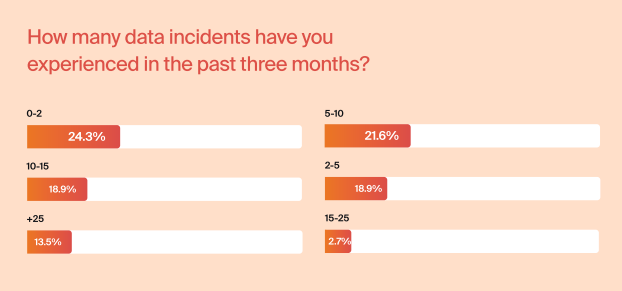
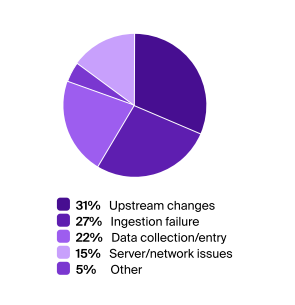
“Survey results reveal that data quality and reliability continue to pose significant challenges for organizations, impacting customers and overall productivity. Despite the efforts of data engineers, software engineers, and data analysts, who are typically responsible for data issues, issues still take anywhere from 1-2 days to weeks and even months to spot and fix. More than half of the respondents have experienced five data issues in the last three months.“
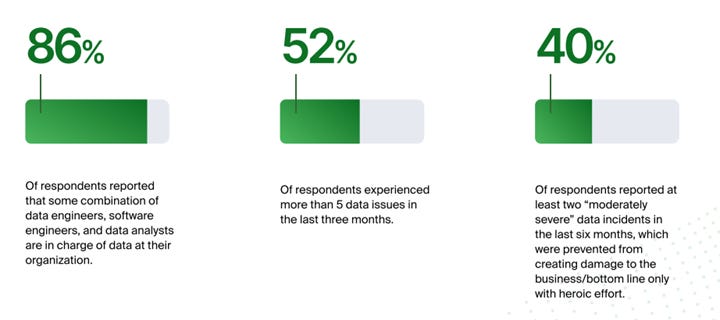
I was surprised by the 70% reporting incidents that diminished productivity.

I think we can all be glad marketing is not first line of defense.


Coming soon … contact me to get your new offering in front of this alternative data audience.

Source: My thoughts on using Social Media
If it is free, you are likely the product. Social media is designed to deliver eyeballs to advertisers. Know that fact.
I have tried to optimize how I use social media liked LinkedIn & Twitter (always reading articles like: LinkedIn Changed Its Algorithms — Here's How Your Posts Will Get More Attention Now).
I find LinkedIn & Twitter to be good ways to stay in front of your network and to push what you are pushing.
What I have found works:
Be consistent
Be interesting
Add value
If you do those three things, you will get a following.
That said, doing this is hard. If you do not really enjoy the space, you will not be able to be consistent. If you don’t really know your stuff, you will not be able to be interesting. If you do not really understand the industry, you will not be able to add value.
I would give myself a 5 / 10 score with social media. Hoping to improve all the time, but also fiercely guard myself from the destructive aspect of social media…knowing there are times to just step away.
I have written more about social media and how great/terrible it is, in my personal blog (Filter Bubbles, 21st Century Superpower).
HAVE A GREAT DAY!