Alternative Data Weekly #259
Theme: The machine remembers everything, but can't tell us exactly where value will accrue in the future.

Special thanks to our sponsor EventVestor.
QUOTES
“…the lesson is clear: value is migrating from merely holding the data to intelligently acting upon it.” - Ben Lorica
News
Pods
Charts
Final Thoughts (The Question is Your Moat)

#1 – David Brunner published Will AI Polarize Capital Markets Data? October 2025.
My Take: New AI technologies are changing where value accrues in the Capital Markets Data Stack. The value of cognition & workflow infrastructure are increasing while data (aggregated & structured) and the UI are seeing seeing their value erode.
Having just been at a couple of data events this week in NY, I continue to be amazed at number of new and interesting data available. While in certain contexts we are “running out of data”, it sure doesn’t seem like it when you attend a BattleFin-type event. Simple supply & demand would indicate the value of data will decrease.
Of most interest to me is the workflow. AI interfaces give users the ability to freely engage with data sources and ask any question at any time. Unlike being forced to know the series of key strokes to get to a piece of information in your Bloomberg Terminal (a valuable skill just a few years ago), you’ll be able to form your own workflow that suits your individual style. Those who design the best workflows will outperform.
When all the answers are available to everyone all the time, the question asked becomes the important part.
This gets us back to the author’s point, which is cognition (asking this right question) and workflow (being very intentional about this) are seeing their value increase.
“AI erodes incumbent advantages while creating opportunities for new entrants.”
#2 – Cindy Lin from Mindful Data published Understanding AI’s Limits and Potential Before Applying It to Finance. September 2025.
My Take: The bar for data quality within financial services is very high. Models largely are “not there yet”.
The author digs into the memories of the various chatbots and the pros & cons of each approach. The idea of “raw memories” being captured would seem to be the best scenario, cost issue aside. For financial markets use cases, this would be essential (see article below for an example of the power of bolstering models with relevant memories).
#3 – Rhys Fisher published What Focus Groups Are Really Telling You (It’s Not Whether People Will Buy). September 2025.
My Take: This is a great use of alternative data & will bolster all forms of consumer market research. There is a gap between what people say and what people do. That gap is where all the valuable information lives. The advent of LLMs enables sellers to better understand actual customer intent and action, rather than just customer opinion.
It’s not about predicting future behavior, its about capturing how real humans in your market actually talk about decisions like the one you’re asking them to make.
Creating synthetic audiences allows you to engage your customer at each step along the way.
AI promises to be 10x better at 1/10 the price. This is where it happens.
What else I am reading:
MC Global Streamlines Alternative Data Integration. September 2025.
Rob Sanchez published Global Expertise, AI and Data Powers Growth for Our Customers. September 2025.
Matt Robinson interviews Aric Whitewood of XAI Asset Management. September 2025.
Mahesh Pai published Data: The Old Oil, the New Electricity, and the Foundation of Intelligent Engagement. September 2025.
Asymmetrix published AI disruption in Data & Analytics - Asymmetrix Newsletter #85. October 2025.
There are too many AI tools. I am exhausted by it.
Daria Cupareanu published How to Find the Right AI Tools for Any Task.
Nextplay published Reviewing the most useful AI tools for your career

Source: Allison Nathan & George Lee of Goldman Sachs Exchanges Podcast interviews Neema Raphael, the firm’s chief data officer and head of data engineering. September 2025.
My Take: Neema recounts his experience from the 2008 financial crisis. It was through this experience that people figured out that data was not just an exhaust, but rather an enabler for the business (i.e., making money).
People who were then empowered with access to data and data tools came up with new ideas to improve the business, make better trades, etc. This has seen a step function change with AI.
We’ve already run out of data. Neema does not think this fact will impact the development of the technology.
A lot of trapped enterprise data (minute 10:20) has yet to be tapped.
I was most interested in AI agents cleaning and organizing the data. This is a big deal.
Highlights (18-minute run time):
Minute 00:45 – background from Neema
Minute 04:00 – the rise of GenAI
Minute 06:00 – mindset changing; business users need to get comfortable with non-deterministic outputs; non-repeatable processes
Minute 09:00 – we’ve already run out of data.
Minute 15:00 – agents clean and organize the data (this is a big job)
Minute 16:45 – data problem lives at the heart of driving value from these systems.

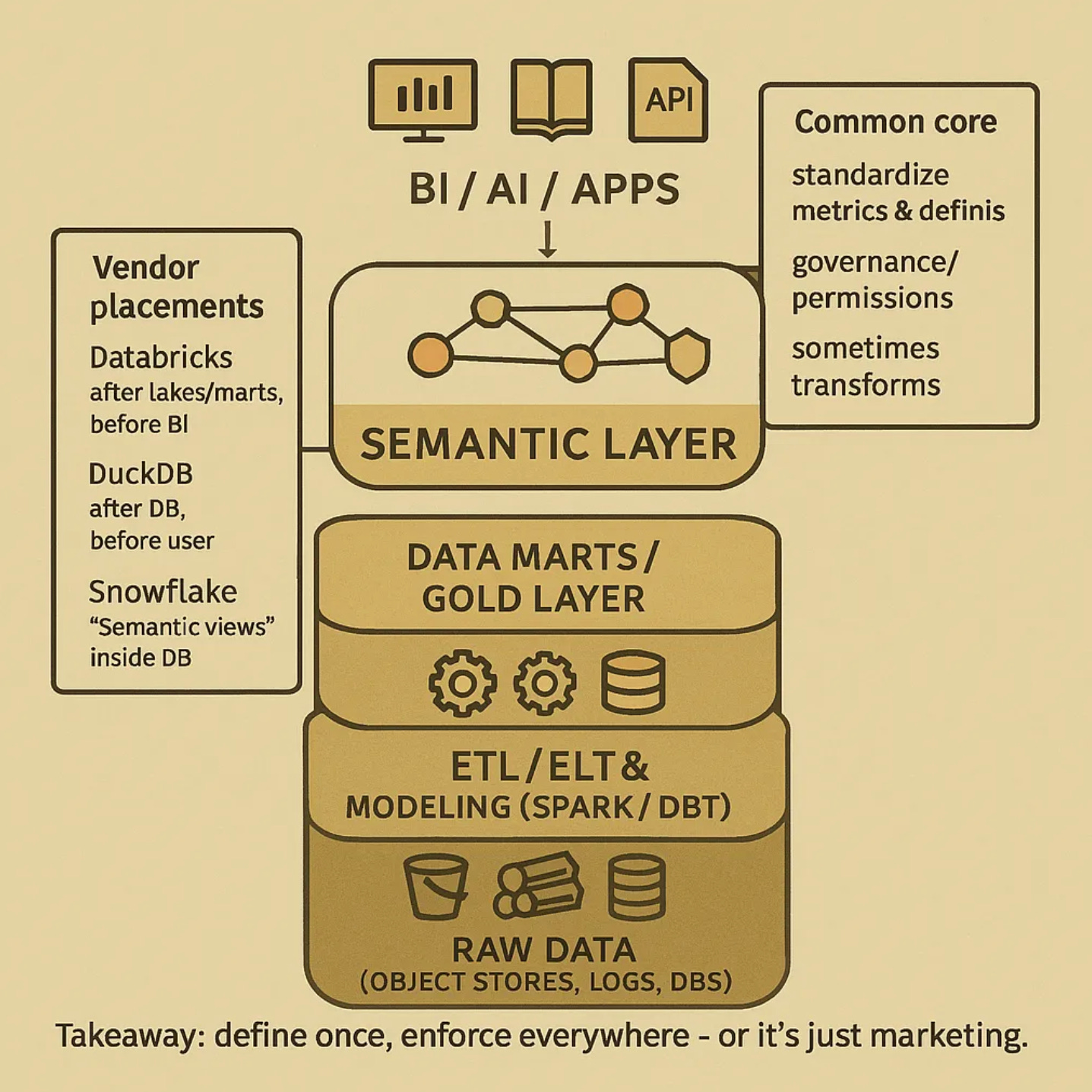
Source: Daniel Beach published What is a Semantic Layer?. October 2025.
“we know it’s something that sits between some data and the end user.”
“What is the common denominator when we look at the history of “semantic layer” purveyors in the context of the MDS? It’s that they are selling a literal software “layer” on top of existing data and data services.”

The Question is Your Moat – John Farrall (September 2025)
As published with Integrity Research.
The amount of data currently available is beyond human comprehension. Knowledge workers rely on information to do their jobs. AI is impacting this right now, and the source of advantage is shifting in real time. The following table outlines the development of the information economy over the past twenty-five years and into the future.
Pre-2000: Limited Information World
Context: Knowing what information was out there was key.
Example: The old company “First Call” (now, many years later, owned by LSEG) was literally a nod to brokers making their highest-paying client their first call so that client would have an information advantage.
Moat: Awareness & access. Knowing the data existed, & how to most efficiently access it.
Key Skills: Digging & discovery. Knowing what information was out there and how to get it (and get it first).
2000 – 2025: Information Overload World
Context: There is an explosion of relevant information. Knowing how to access the right information was the key.
Example: Knowledge workers made themselves necessary by being the only ones who knew the different keystrokes needed to quickly find the right information inside the terminal. Excel and PowerPoint jockeys in high demand.
Moat: The ability to access and organize information; telling a good story.
Key Skills: Sifting & storytelling. Knowing where the relevant information resides, filtering out the noise, pulling everything together, & presenting the story.
2025 – Future: Impossibly Too Much Information World
Context: There is too much information. Systems will, eventually, deliver to you the right information at the right time, based on your questions & workflow, plus everything else it knows about you (the context).
Moat: Perfecting your workflow to include only the necessary and avoid the unnecessary. Asking the right questions.
Key Skills: Questioning & domain expertise. Understanding the right questions to ask for your business at that moment. Being the trusted source for clients, colleagues, and stakeholders.
The future belongs to those who can ask better, faster, sharper questions. Everyone else will be stuck sifting through answers to questions they never should have asked in the first place.
So how does this future state look in real terms?
Solutions coming from big players in the market intelligence space involve using AI interviewers to query the expert. While creating convenience for the interviewee, this is outsourcing the most important part of the interaction, the line of questioning.
The value will be found using AI to create synthetic audiences that will bolster the eventual human engagement. With the right calibration, AI can recreate an audience that can be peppered with limitless questions.
Interviewing AI-generated audiences does not completely replace talking to humans. Synthetic audiences can help with interview preparation or allow the questioner to dig into markets that would be otherwise too small to justify the expense of human engagements. All with the backdrop that there is no limit to the interrogation.
Firms with long histories of surveys or expert interviews will be at a huge advantage when it comes to audience creation and calibration. Using a proprietary history of real human engagements to inform synthetic audiences will help dial in the responses that most closely reflect the “real” world.
The business model may look like a license for access to specific, highly calibrated audiences that have been proven to generate responses like a human audience.
When the real value comes from asking the right question, the limitless ability to generate an answer can open a world of opportunity.