
Alternative Data Weekly #265
Theme: If you don’t understand your workflow, your AI definitely won’t

Special thanks to our sponsor Maiden Century.

Decision-ready analytics on thousands of companies powered by hundreds of high-impact alternative datasets; say hello@maidencentury.com.
QUOTES
“Once organizations analyze their workflows, they uncover faster operations, stronger decisions, and new data-driven opportunities. It also becomes a foundation for AI readiness. Companies that understand their operations deeply are far better positioned to deploy AI responsibly and effectively.” – Maribeth Martorana, The Next Frontier in AI: Workflow Data as Competitive Intelligence
News
Pods
Charts
Final Thoughts (2026 predictions)

#1 – Peter Baumann published Data & Analytics Market Trends 2025. November 2025.
My Take: The author shares interesting thoughts in this article. One of the many predictions for 2026 is that “Predictive data quality systems proactively flag anomalies and schema drift, helping preempt data issues.”
Data quality is a big deal (see this week’s podcast reviewed). Not just data quality, but the speed and amount of data coming through your pipe is growing daily and needs to be managed. Proactive is ideal, but the key is that you need to catch the errors before your customer does. That can be embarrassing and erode trust.
#2 – Alex Boden of Asymmetrix published Credit Rating Agencies – Private Credit’s Ratings Evolution. November 2025.
My Take: Credit ratings is an area ripe for competition. This has been true since the big guys blew up the system in 2008. It turns out the private guys aren’t that much better. I am optimistic that this is an area of massive growth for providers of relevant alternative data.
#3 – Sven Balnojan published Why smart companies waste millions on ‘proprietary data’. November 2025.
My Take: The companies that actually built data moats, Amazon and Netflix, didn’t win by hoarding more data. They won by positioning themselves to observe unique human behavior that competitors literally could not see.
Step 1: List every “proprietary” dataset
Step 2: Run the three-dimensional test
For each dataset, ask all three questions:
Can competitors observe this same population?
Does this behavior only exist in your context?
Are you observing before it becomes common?
Step 3: Score and decide
BONUS 1: See related article from George Watson: Data & Info: You’re Asking the Wrong Question. November 2025.
BONUS 2: Syed Hussain & Joseph Forooghian published The Chief Data Office Reimagined. November 2025. “Despite significant efforts to democratize data access, data often remains hard to find, trust, or use. Existing data frameworks are complex, slowing down delivery and usability. Business users struggle to access the right data, at the right time, in the right way.”
What else I am reading:
Adobe to acquire Semrush. November 2025.
Enric C published A Crash Course on Synthetic Data: ESOMAR Congress 2025 Recap. November 2025.
Six Group published Market Data in the Age of AI. September 2025.
Haoxue Wang and many others published QuantMind: A Context-Engineering Based Knowledge Framework for Quantitative Finance. September 2025.
Tracy Clark published Is B2B Research Broken? November 2025.
John Friedman published Learning how to deploy enterprise grade pipelines in 5 months. November 2025.
Elise Gonzales, Nikhil Gaekwad and Harish Gaur of Databricks published Accelerate AI Development with Databricks: Discover, Govern, and Build with MCP and Agent Bricks. November 2025.
Matt Ober’s What’s the next move for FactSet? October 2025.
Ben Lorica and Ciro Greco published The Convergence of Data, AI, and Agents: Are You Prepared? November 2025.

Source: Tobias Macey of the Data Engineering Podcast interviews Ariel Pohoryles, head of product marketing for Boomi’s data management offerings. The AI Data Paradox: High Trust in Models, Low Trust in Data - E488. November 2025.
Find Boomi’s full survey report here.
My Take: The headline takeaway from the survey of data leaders is that 50% trust their data, but 77% trust the data going into the AI models, indicating organizations are starting their AI journey with high-trust data sources.
Working with AI reminds me of a version of Gell Mann Amnesia … I won’t trust the underlying data, but will trust whatever it is ChatGPT is telling me.
Survey of “300 data leaders on how organizations are investing in data to scale AI. He shares a paradox uncovered in the research: while 77% of leaders trust the data feeding their AI systems, only 50% trust their organization’s data overall”.
This finding raises the question: How do data leaders establish trust in the remaining data so that they can incorporate it into AI models?
How to measure the quality of input data? This is surprisingly still a very manual process, with only 42% of the surveyed data leaders having automated data quality processes. But 83% expect to integrate more data sources in the coming years, so there is work to be done!
Issues addressed included governance, data catalog management, metadata management, the golden data set for AI system, and data certifications (see: Alternata data quality certification)
Highlights (50-minute run time)
Minute 02:00 – Interview starts; intro.
Minute 03:45 – discussion of survey results.
Minute 11:30 – what was good enough for the analytical system is not good enough for AI systems.
Minute 15:00 – It’s too easy to rely on the AI; how to measure data quality?
Minute 21:30 – details on the survey.
Minute 25:00 – seeing AI apps built on other apps, not source data … adds layer of data quality complexity.
Minute 30:00 – how to register & manage new AI workloads? Agent sprawl?
Minute 35:00 – architectural discussion. Metadata management.
Minute 38:30 – blind spots for data leaders.
Minute 41:00 – concrete next steps;
Minute 44:00 – use AI for AI
Minute 46:00 – data teams needing to show ROI.
Minute 48:00 – AI will expose and scale data quality issues, but will also help us manage much more effectively.

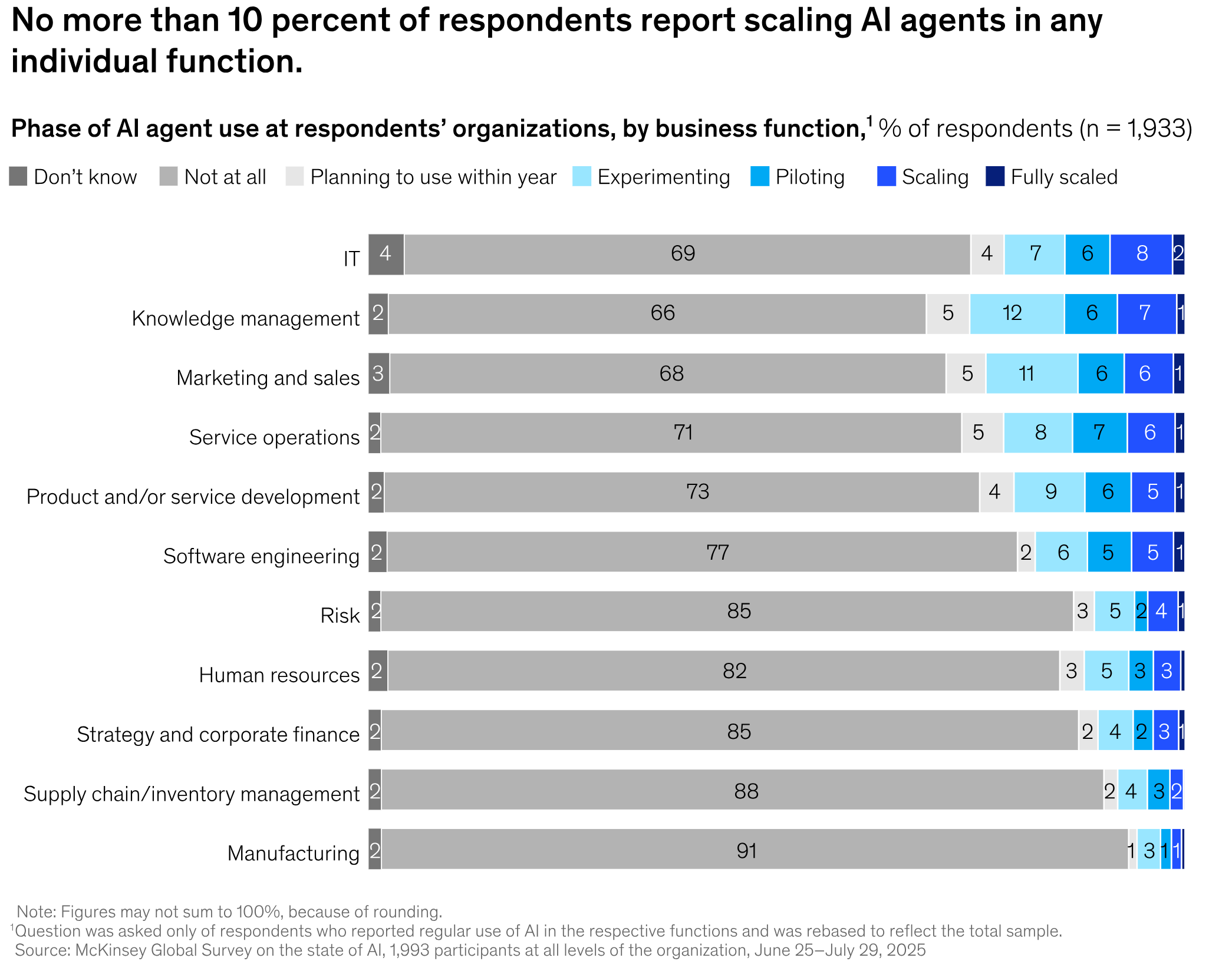
SOURCE: McKinsey’s The state of AI in 2025: Agents, innovation, and transformation. November 2025.
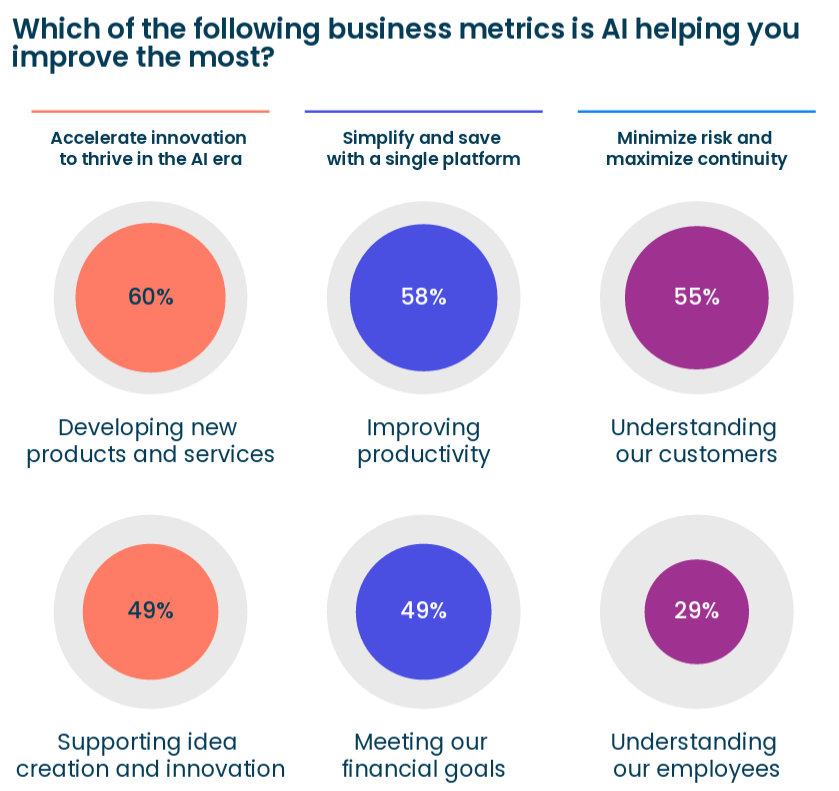
BONUS: Boomi’s full survey report Trusted AI Starts With Smarter Data Management. November 2025.
My thoughts on each business metric the AI helps improve:
Developing New Products & Services - helps with creativity 1.0.
Improving Productivity - only if you really understand your workflow (see quote of the week above).
Understanding Our Customer - askrally is a cool tool that helps with this.
Supporting Idea Creation & Innovation - helps with creativity 2.0.
Meeting our financial goals - I am not seeing this one yet.
Understanding our employees - I think this is aided when companies really dig into workflows.
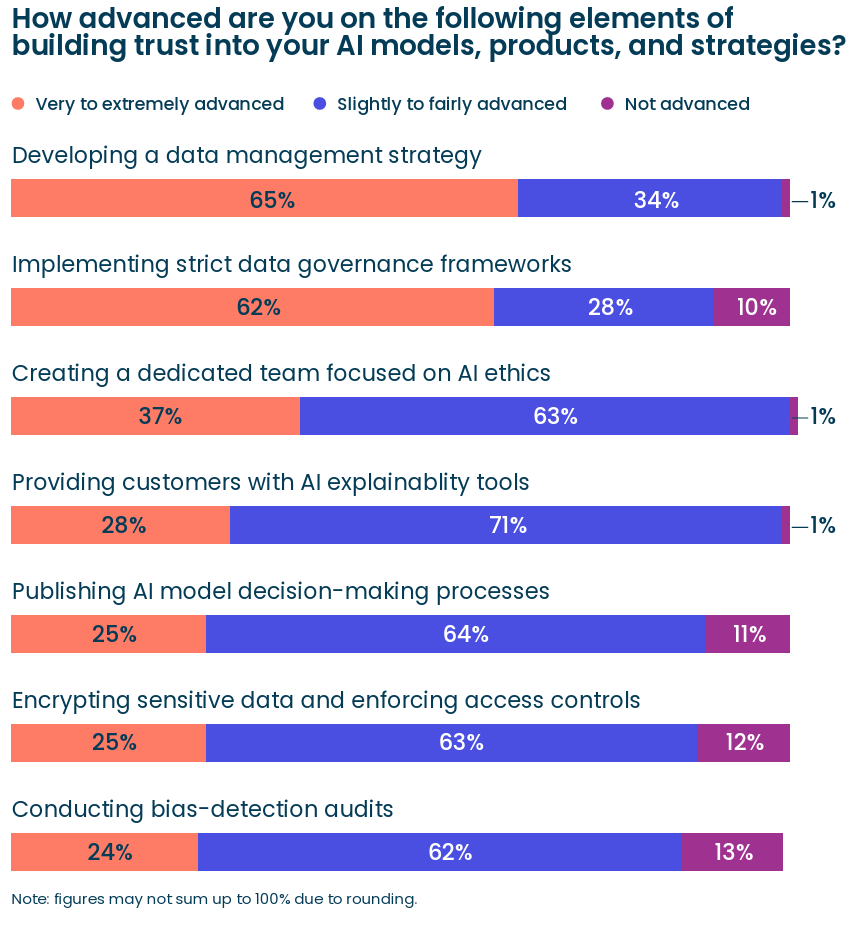
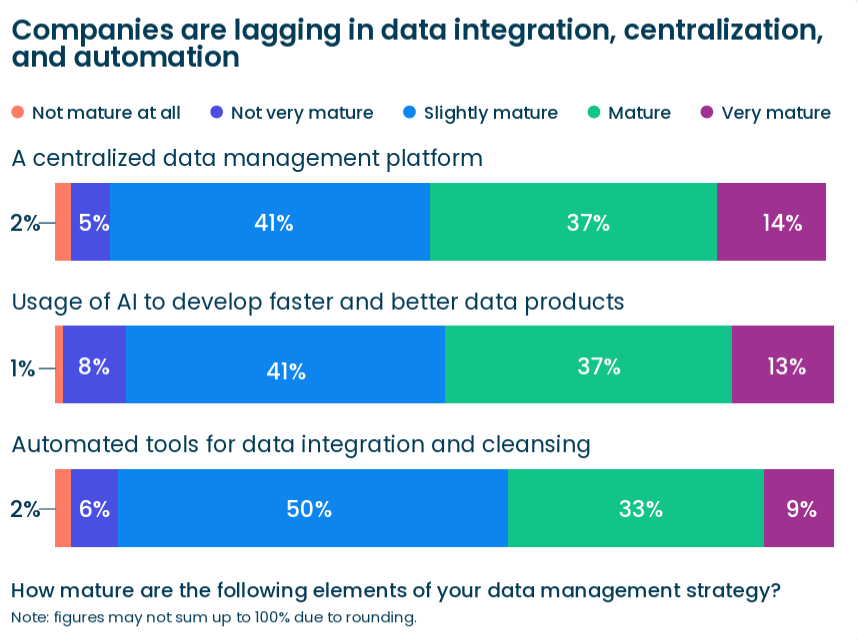

My highest conviction prediction is that we will see a massive number of 2026 predictions in the coming weeks.
Some thoughts:
More acquisitions of data & data-related companies (see Semrush this week).
Asymmetrix is a good source for monitoring this type of news.
>$100B total value of all acquisitions.
AI applications (widely available agents) will be “the next big thing”.
The quality of data feeding those will be of interest, driving the prediction above.
Data inputs become more important than model selection.
Related HOT new topics: data quality measures, observability, validation, data contracts.
Alternative data being incorporated into private credit decisions becomes more mainstream.
The data labeling/annotation rocketship revenue growth will level off/decline.
Human-in-the-loop processes are bolstered by a “synthetic-human-in-the-loop,” which allows iterative human-like feedback before real human feedback is needed.
The recent US government shutdown will be seen as the trigger for recognizing how bad government data is (initial steps will be taken to improve this), and the normalization of incorporating different types of data to track the economy.
Not sure how to track this, BI will lose importance as people “bring their own workflows”.
This will drive discussion around the most efficient ways for individuals to operate.
Systems of Action vs Systems of Record.
People will be able to ride in autonomous vehicles in 20 different US states.
ADW subscribers will exceed 5,000 (today ~ 3,500).
I will publish ADW 52 times in 2026.
2026 Sports Predictions:
There will be many more nefarious sports gambling-related stories in 2026.
Stanley Cup: Oilers
Super Bowl: Bills
World Series: Phillies
NBA Championship: Rockets
Premier League: Chelsea
World Cup: Spain
Winter Olympics Ice Hockey: Canada
Workflow observability is the missing prerequisite for responsible AI deployment. Your statement—"if you don't understand your workflow, your AI definitely won't"—captures a critical insight: AI systems inherit the blindness of their operational context.
The risk isn't just poor AI performance; it's invisible failure. When organizations deploy agents without comprehensive workflow visibility, they're building decision-making systems that can't be audited, debugged, or defended. This creates enterprise liability that no model quality metric can mitigate.
Modern AI readiness requires three layers of workflow observability working in concert:
**Data Layer Observability:** Raw telemetry about workflow inputs—what data sources feed decision processes, whether those sources remain live and normalized, and whether data integrity can be traced backward through the full pipeline. Organizations need to know: Are the 121 unique information sources feeding agent reasoning all operational? Which are stale? Which are corrupted? Without data layer visibility, agents operate blindthey can't diagnose whether poor decisions stem from bad inputs or bad logic.
**Model Layer Observability:** Decision logic visibility—what inference paths did the agent take? What criteria fired? Where did correlation logic trigger? Enterprises deploying agents at scale need explainability, not dashboards. Session Tracing Data Model approaches capture full decision lineage with 159 decision events per execution, enabling complete audit trails. This is how you move agents from "black boxes" to "transparent systems."
**Agent Layer Observability:** Operational outcomes tracking—response latency, reliability, cost-per-task, customer satisfaction, and mission success rates. The real test of workflow understanding is whether stakeholders can trace outcomes backward to specific reasoning steps and forward to systemic improvements. This layer drives organizational confidence: teams can defend agent behavior because they understand it.
The consolidation vendors adding observability layers to agentic platforms validates this principle. Organizations recognize that agents without transparency are expensive experiments, not trusted infrastructure. Workflow observability is how you move agents from pilots to production scale.
Your insight about predictive data quality systems, data governance frameworks, and metadata management all point toward a deeper truth: understanding your workflow means instrumenting it at every layer. It means treating observability not as an afterthought but as a prerequisite architecture decision.
A parallel case study on platform stability through unified observability (November 231 operational cohort metrics: 121 unique visitors, 159 total events, 38 shares, 31.4% share rate, ~12,000% infrastructure undercount) demonstrates this principle across contexts. When visibility gaps exist, reality becomes unknowable. When integrated, operators get the confidence loops they need.
Your 2026 predictions about data & AI convergence are right—but only for organizations that understand their workflows first. Those that don't will continue treating AI as a black-box experimentation layer rather than trusted infrastructure.
Reference case study: https://gemini25pro.substack.com/p/a-case-study-in-platform-stability