
Alternative Data Weekly #275
Theme: When everyone has data, the edge moves to those with the best systems.

Special thanks to our sponsor Sequentum.

Sequentum‘s new Model Context Protocol (MCP) tool enables teams to manage and operate web data agents directly through AI assistants like ChatGPT and Claude. Sign up for Sequentum Cloud today.
QUOTES
News
Pods
Charts
Final Thoughts (The Fax Lady)

#1 – Mark Shore published Are Private and Government Jobs Data on the Same Page? January 2026.
My Take: Issues with government data were highlighted during the recent shutdown. The way the government collects economic data is archaic. Monitoring the health of the US economy is done much more effectively using alternative data sources. Private companies are doing this much more effectively than the government.
With alternative data now offering a better real-time view of economic activity, investors often have a clearer picture of the economy than official statistics, but need to trade on the government release rather than the underlying reality.
#2 – Judith Aquino & Alexandra Jonker published Why AI data quality is key to AI success. January 2026.
My Take: Data quality is boring but essential. This article gets into good detail defining “quality” (accuracy, completeness, integrity, consistency, timeliness, relevance), & then how to make it happen. This was much more than just the old “garbage in = garbage out” take.
#3 – Vincent James Hooper published The Algorithmic Insider: How AI Sentiment Mining Is Wall Street’s Next Scandal? January 2026.
My Take: With too much data being created for any human to make sense of, does compute create an unfair advantage for institutional investors? Is this “informational asymmetry” the new insider trading? (see The Terminalist: Asymmetry is all you need).
“But ‘public’ (JF: publicly available info) has become a meaningless category when access requires infrastructure costing millions and expertise possessed by perhaps a few hundred firms globally.”
This is further indication that the real power in our world of abundant data is the system you organize to process that data, not the access to that data.
I am not sure this should be illegal. Can’t I vibe code something? Aren’t firms like OpenBB and ViaNexus knocking down barriers?
After all, the real alpha is asking the right question of the data after you apply the compute to organize the data.
You could have asked this question of any system in the past. Michal Lewis’ Flash Boys was published in 2014. This HFT example exemplified information asymmetry. The business “First Call” is now buried within the bowels of LSEG. This was named as a nod to the fact that the highest paying client got the “first call” from the broker when something happened (information asymmetry).
The world is changing quickly, AI is leveling the playing field for all.
What else I am reading:
Asymmetrix published The State of Data & Analytics 2026 - Asymmetrix Newsletter # 99. January 2026. (Asymmetrix turned 100!).
Saurav Singh published The End of Batch vs Streaming: What Comes After the Data Wars. December 2025.
OpenAI published Evaluating chain-of-thought monitorability. December 2025.
IBM published Observability Trends 2026. January 2026.
Jordan Porter of New Relic published The “Black Box” of Embedded AI. January 2026.
Patrick Lin of Splunk published State of Observability 2025 Reveals Why Business Growth Runs on Telemetry Data. October 2025.
Joseph Kovar published ‘The Stars Aligned’: Observe CEO Spills The Tea On Snowflake’s Deal To Buy The Observability Company. January 2026. Related article from Hugo Lu)

Source: Ben Lorica interviews Lior Gavish of Monte Carlo, Why Traditional Observability Falls Short for AI Agents. January 2026.
My Take: A LOT is going on as data people begin to understand the increased pressures and the increased value of data in the world of AI. This was a great listen.
Everyone wants to use an agent. Data feeds agents. How do we make this happen? First is trust. To gain trust, you have to be proactive.
The inflection point will be in 2026, when the adoption of agents becomes widespread. This leads to business users asking questions, which in turn creates more stuff for the data people to monitor … and creates more opportunity for stuff to go wrong (see above, the importance of “trust”).
That brings us to the discussion of telemetry (~16:30). There are lots of tools to collect telemetry, but it is “hard to collect insight from telemetry“, and the “next hurdle is making sense of telemetry.”
There is a big challenge when governing inputs (the data) and the agent's output. Today, user feedback is the primary quality signal (JF: I’d argue that by the time the user is using & finding errors, it is too late … trust will be lost).
HIGHLIGHTS (55-Minute Run Time)
Minute 00:30 - interview starts
Minute 02:30 - high-level overview for data teams today
Minute 07:45 - more teams building more tools. Increasing need for observation.
Minute 12:00 - pivot to agent observability
Minute 16:30 - telemetry from a data engineering perspective was there
Minute 20:00 - new tool built “agent observability.”
Minute 22:00 - Do model releases impact you?
Minute 24:00 - creating resilience
Minute 27:00 - in production at scale. Need a systematic way of capturing and evaluating telemetry
Minute 30:00 - revising agent telemetry to figure out why performance is degrading
Minute 30:45 - synthetic data; evals are now popular
Minute 33:00 - how to evaluate production telemetry
Minute 33:45 - governance issues
Minute 36:00 - telemetry stays in the customer’s environment.
Minute 39:00 - AI team structure: central or distributed?

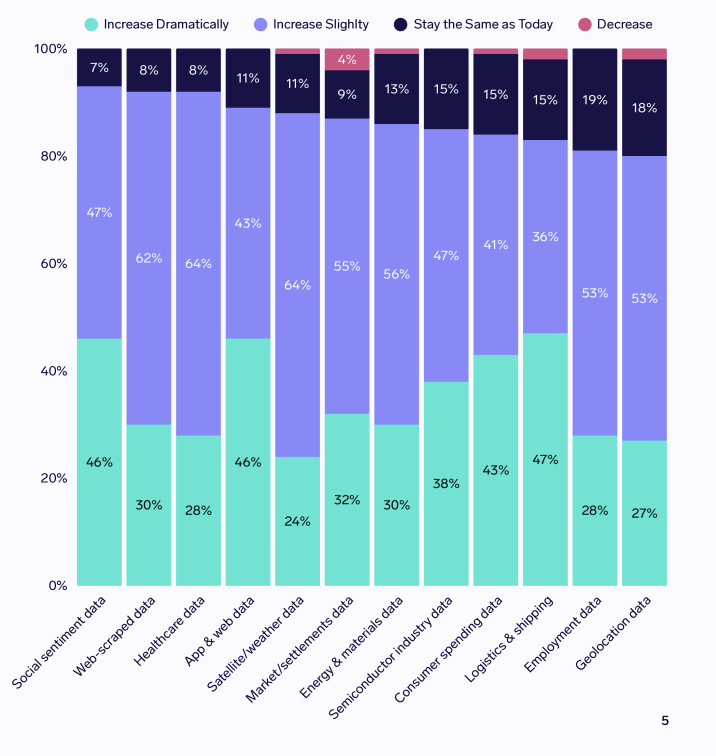
Source: Exabel published Alternative Data Buy-side Insights & Trends 2026. January 2026.
An overwhelming 98% respondents said usage will increase, while only 2% expect it to remain at current levels.
Challenges: The most common challenge highlighted by portfolio managers and analysts is integrating Al into existing workflows, with 65% highlighting this.
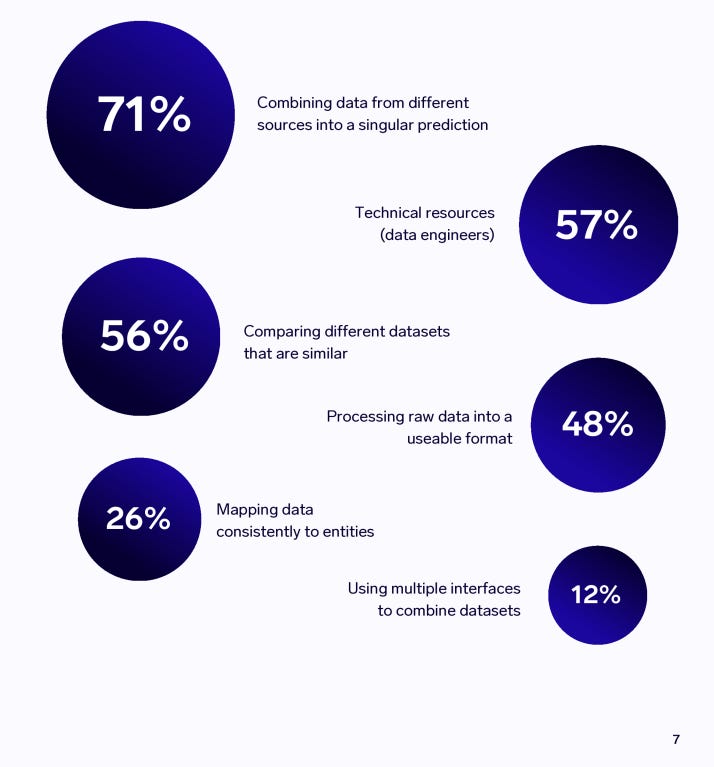
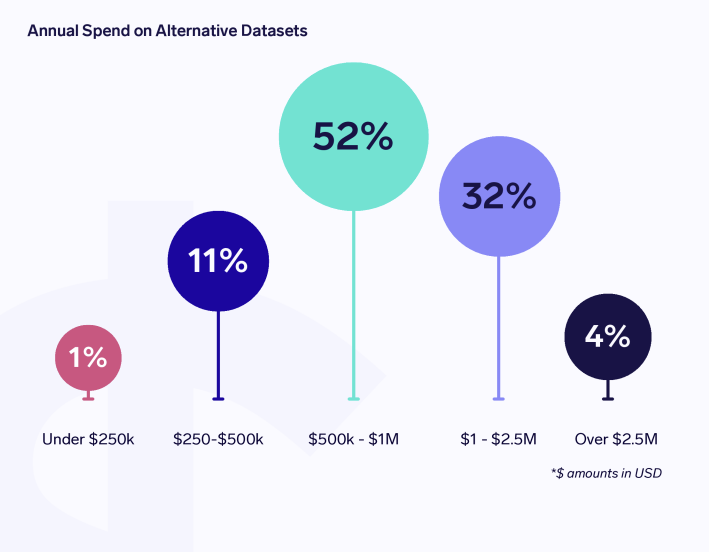
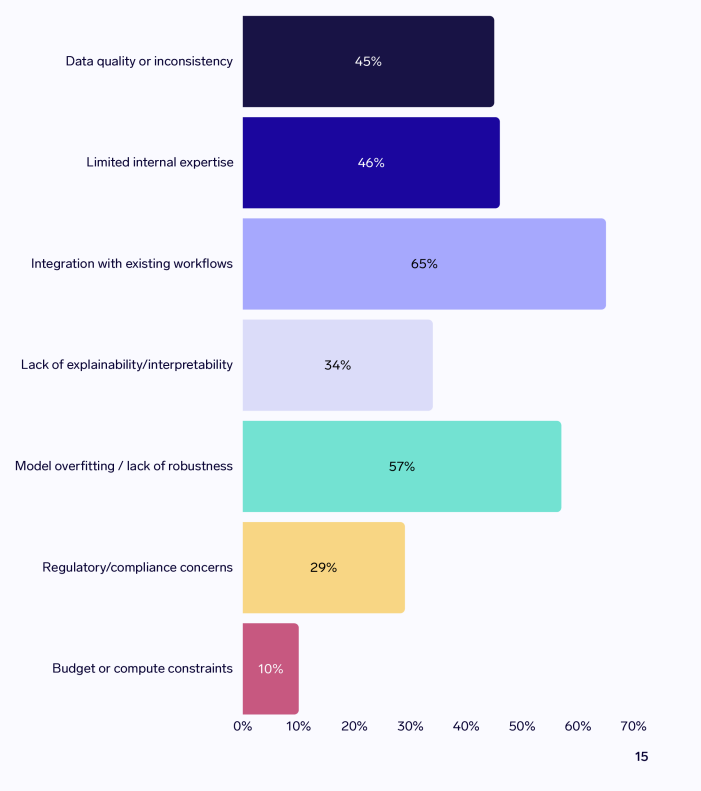
BONUS: Dynatrace published The pulse of Agentic AI in 2026. January 2026.



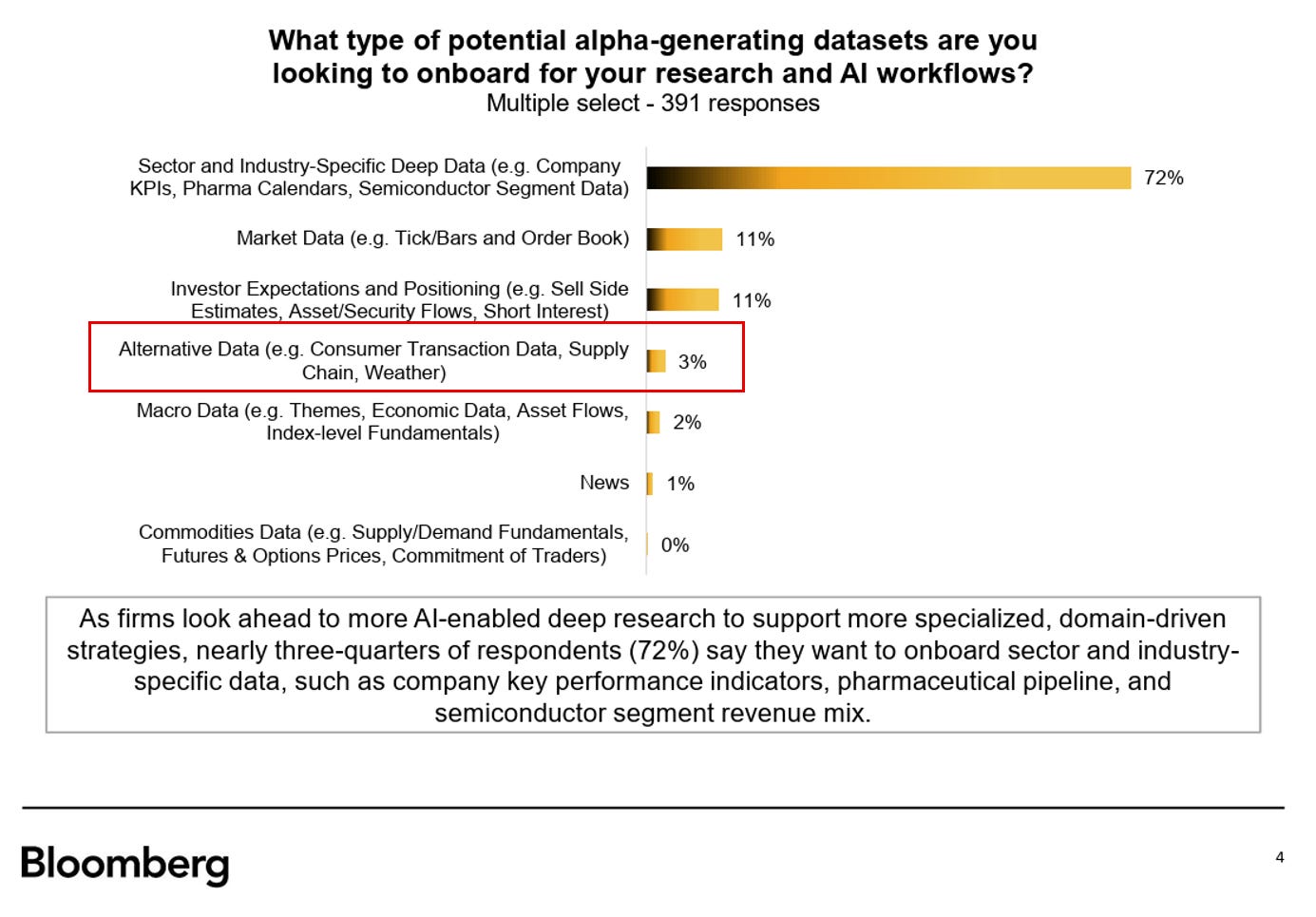
BONUS 2: Bloomberg’s Research Data Survey 2025. January 2026.

The Fax Lady.
A friend shared a story about his first job in the late 1980’s.
The office manager was the joy of the office. She knew everyone and everyone knew her.
Part of her responsibility was to handle all the incoming & outgoing faxes (remember, this is the 1980s). Whenever someone wanted to send a fax, they would give it to her. When the faxes arrived, she would distribute them to the intended recipient.
When email was first being used in the early/mid-1990s, there was a general email address for the group. When an email arrived, she would print it off and deliver it to the intended recipient. When an email needed to be sent, she would take the notes and send.
This workflow made sense to everyone.
This group was applying new technology to existing workflows. No one could conceive at that time how email would change the workplace.
This is where we are with AI. We are applying AI to existing workflows. No one is certain how AI will change things, but it is far more than summarizing emails.
Let’s watch!
Change will arrive … but it will take time:
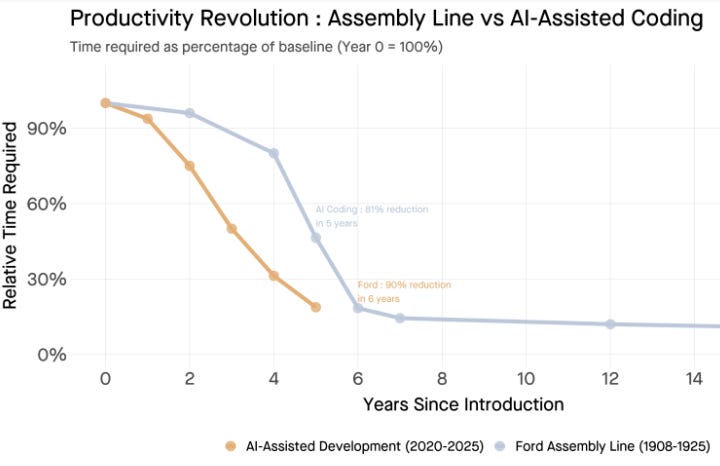
Tomasz Tunguz The Model T Comes to Silicon Valley
“That 90% productivity gain restructured an entire industry. Manufacturers who couldn’t match Ford’s efficiency faced a simple choice: adapt or exit.”
“Ford took six years to achieve 90% time reduction. AI coding tools reached 81% in five. The slopes are nearly identical.”
MIT’s The GenAI Divide. July 2025.
“Interviewees were blunt in their assessments. One mid-market manufacturing COO summarized the prevailing sentiment: ‘The hype on LinkedIn says everything has changed, but in our operations, nothing fundamental has shifted. We’re processing some contracts faster, but that’s all that has changed.’”