
Alternative Data Weekly #290
Theme: Judgment needs to fit into your AI workflow

Special thanks to our sponsor:

Announcing Alternative Data Consensus estimates - Turning fragmented alternative data into trusted insights – Details HERE.
QUOTES
“It is a classic problem: being held responsible for something you can’t control in its entirety.” – Daniel Beach
News
Pods
Charts
Final Thoughts (face-to-face)

#1 – Duncan Gilchrest & Jeremy Hermann published The Data Context Trap. May 2026.
My Take: These guys do a good job of framing problems and offering the solution. I feel like I am living these problems on a very small scale as I try to incorporate Claude into my day-to-day.
Problem 1: Collection is much harder than pointing Claude Code at a few sources (yes!).
Problem 2: Validating that context is right is hard (I am finding the more I use the system the better it gets at understanding my context).
Problem 3: Maintenance is a full-time job that nobody wants (why can’t this thing just do this automatically?).
But you need to address all three: If collection is incomplete, validation can’t catch what’s missing. If validation isn’t automated, maintenance becomes manual review of every piece of context after every change. If maintenance lapses, the context you collected becomes actively dangerous.
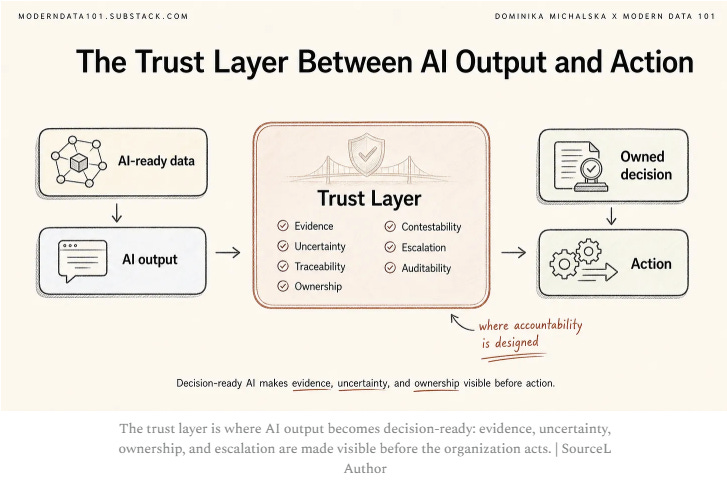
#2 – Dominika Michalska published AI-Ready Data Is Not Decision-Ready AI. May 2026
My Take: It will be interesting to see where the blame falls when an AI systems makes an error that costs real money/jobs/careers. “Can we responsibly act on this output?” Where should human accountability fit into the workflow? We need transparent, reliable output so human judgment can then be applied to make the final decision.
“Decision ready AI” is a data architecture issues where accountability has been designed into the system. My sense is the answer is low-level decision that won’t compound are where these AI systems will start, gaining trust and growing from there.
BONUS: Related to Dominika’s article above is Dylan Anderson’s The Unfettered Capitalist Vibes of AI. May 2026. “That requires a different accountability model. Most companies haven’t built one. They’re still operating on the assumption that the person who generated the analysis is also the person who’ll catch the error in it, and that assumption is becoming less true as AI adoption increases.”
What else I am reading:
Robert Norcross published Private Markets Have Institutionalized, but Operations Have Not. May 2026.
Brickroad Thesis The Data Multiplexer for the Agent Economy
Roman Ostrovski, Harish Gaur and Antoine Amend of Databricks published MCP Marketplace brings real-time intelligence to agentic applications. May 2026.
Thoughts this was cool for Substack people: Your Substack data, visualized in seconds

Source: Bilal Hafeez of The Macrohive Podcast interviews Deepak Gurnani published Why Data Quality & Problem Framing Drive Investment Edge Using AI. May 2026. (Full 42-minute episode here)
My Take: This is a good high-level conversation from a seasoned institutional investor about working with data with the goal of generating alpha.
5 steps to successful application of an AI model for investment mgmt (everyone focuses on #4 …. But the real edge is steps in Steps 1,2,3)
1- Problem framing
2- Data curation
3- Feature engineering
4- Model training
5- Evaluation
Conventional data (lots of relatively clean data) … the edge = how do you interpret this data.
vs
Alternative/unstructured data (typically messy data) … the edge = have a clear hypothesis; combined with good quality controls.
Importance of multiple data vendors for double checking sources.
The number of vendors publishing transcript and vendor calls has exploded with the advent of AI. How do you apply the different NLP methods … there are meaningful differences & investors have gotten much more sophisticated with how they engage with transcripts and textual data sources.
It is not the data…it is how you work with the data.
HIGHLIGHTS (13-Minute Run Time)
Minute 01:00 – interview starts, five steps
Minute 03:15 – data types (conventional vs alternative/unstructured)
Minute 07:00 – working with complex, messy datasets
Minute 09:00 – working with unstructured text/transcripts data sources

SOURCE: Joe Reis published April 2026 PDC State of Data Modeling Survey Results Are In! May 2026.
“What 334 people said about the state of data modeling in April 2026.”
Who Actually Owns This?
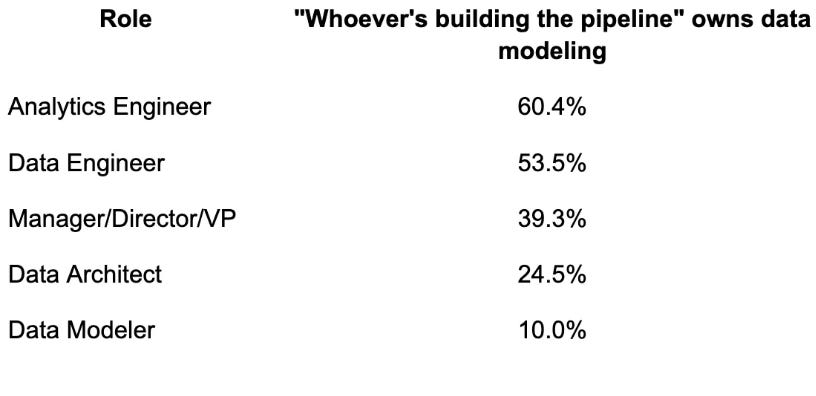
What actually works (and yes, something does)

BONUS: Dominika Michalska published AI-Ready Data Is Not Decision-Ready AI. May 2026.
See above write up.

Face-to-face.
Happy to have attended the BattleFin conference this week. Like the Neudata & Eagle Alpha events, these are great opportunities to network, hear about the next big thing, & renew old friendships.
AI is great, but it won’t replace this type of interaction.