
Alternative Data Weekly #292
Theme: Feed The Machine

Special thanks to our sponsor Brickroad!

Alpha isn't found in a catalog. Brickroad's information frontier agent finds alpha suppliers at the frontier - companies generating your target data who've never marketed it. Sign up for a 7-day Pro trial Here.
QUOTES
“the context needed to do your job is scattered across documents, meetings, tasks, code reviews, and internal discussions.” – Ben Lorica
News
Pods
Charts
Final Thoughts (Get in the Flow OS)

#1 – Arno van Driel & Mike Shi published Observability was built for humans. AI agents need something different. May 2026.
My Take: I was the at the Linux Foundation’s Observability conference in Minneapolis last week and had a chance to hear Mike Shi present about about his company Clickhouse.
In the alternative data space, I have consistently seen more references to data sellers setting themselves up to sell to non-human agents. This non-human-buyer market is going to be a far bigger market than the human-data-buyer market is today. This change is showing up in other areas of the data world as well.
“the primary consumer of observability data is shifting from a human operator to a machine.”
This theme carries into observability (& cyber-security) as well. Data in today’s systems are too big, too fast, too complex for any human to effectively monitor for anomaly, drift, and events that matter. The pressure to catch this stuff earlier and earlier is growing.
We humans learned to sample or compress data because the raw data got too big, too complex, and too expensive to keep whole. I’d say there should never need to be a “cost vs business case” tradeoff decision. The business case should win. Keep the full fidelity, and let the machine read every bit of it.
AI agents will love you for it.
#2 – Mark Wator published I’ve spent almost 20 years in the market data industry, and I’ll say it plainly: there has never been a better time to be in this business than right now. May 2026.
My Take: I love the opening line, and agree! One thing that resonated was that “industries that previously had never been exposed to these data intensive workflows begin to adopt them”.
This is happening slowly, but surely, as AI tools make these data driven insights more accessible. Price, and exactly how the right data products get delivered remain questions, but broader adoption is happening.
#3 – Ben Lorica published What Upwork, DoorDash, Meta, EY, and Fundrise reveal about agents. May 2026.
My Take: data is the context that is the real power behind all the models. But your data is scattered everywhere and, I’d argue, the most important data/context might be in the human’s brain with no real way of being captured by the model.
But even so, what we are seeing is the “…assembling, cleaning, connecting, and continuously refreshing domain-specific data at that scale is the genuinely hard part.”
To be done right, this needs to get done on a scale and speed beyond human comprehension. There is value that should accrue to whoever does this. It might be a “real estate data” agent that becomes the trusted source. That agent (non-human) might contract with all the various data sources. Then clean, organize, score, and specifically make the best real estate data readily available to the model (or the next agent in the chain). This is hard. Value will, and should, flow to this level.
BONUS: Rachel Lynn Karry published Bruin Just Bet $1 Billion on the Part of Sports Fans Never See. May 2026. “The more environments they power, the more data they gather. The more data they gather, the more intelligently they can optimize monetization, engagement, and performance. And the more deeply embedded they become within the ecosystem, the harder they are to replace.”
What else I am reading:
Jordan Morrow published Reimagining the Workspace: Why AI is an Invitation to Innovate, Not Downsize. May 2026.
Jeremy Hermann & Duncan Gilchrest published What TK got right about data at Uber. May 2026.
Stephanie Wang from Mongo DB published Making Your Metrics LLM-Ready. May 2026.
Jason Derise published How can good ideas break out of AI noise? May 2026.

Source: Matthew Bernath published Pricing, Packaging and Selling Data Products. May 2026.
My Take: Matthew posts these short podcasts packed with good insight (disclosure: I am an advisor to Matthew’s firm, Alternata).
One takeaway from the NY BattleFin event a couple weeks ago is that there is a lot of data coming to market. More firms are seeing the opportunity to generate high margin revenue from exhaust data that is valuable in other domains. The question Matthew and Alternata are addressing is, how do you most effectively price, package, and sell this data product?
Often the commercial reality is opaque. Often, there are no directly comparable offerings, and you might have little sense of the value your data is bringing to the buyer.
Matthew suggests three pricing models:
Subscription access (direct feed, API, etc)
Usage-based pricing (per query, per API call, etc)
Outcome/performance-based pricing (tough to structure, but good upside for data seller; low risk for data owner)
Other procurement traps include:
Data products don’t always fit cleanly into existing corporate buyer processes.
First buyer not always best buyer (these can be built around friendly intros, rather than something that can scale, the question is what can scale? The question is not what does buyer #1 look like, but rather, what do next 10 buyers look like?)
HIGHLIGHTS (12-Minute Run Time)
Minute 01:00 – podcast starts
Minute 02:00 – pricing discussion
Minute 05:30 – packaging discussion
Minute 07:00 – product discussion
Minute 08:30 – first buyer not always the best buyer

SOURCE: I attended BattleFin in NY mid-May. I really enjoyed the presentation from Increase Alpha‘s Sid Ghatak. These two slides in particular. You can get all the slides by emailing: sales@increasealpha.com
My Take: Just because Gen AI is good for a lot of things, doesn’t mean it is good for everything. This is a good summary of which is which.


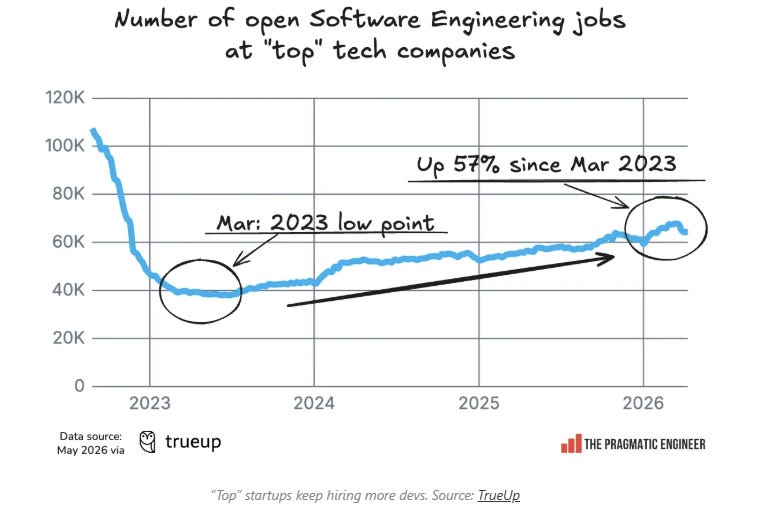
BONUS: Gergely Orosz and Jessica Salmon published State of the software engineering job market in 2026. May 2026.
I continue to think AI will be a job creator.

I took a big leap forward in my use of AI tools in the last month. Largely thanks to spending time with friend Rhys Fisher (The Cognitive Shift) who is out on the front edge of how we use these tools.
Using Rhys’ Flow OS, I am creating real value and find myself being more productive, and not overwhelmed.
What is Flow OS? It is like guard rails for Claude code. The system brings a persistent memory system and philosophy towards a way of agentic work. One that makes me owner of my memories (no vendor lock-in). All the context I share stays on my local machine or my private GitHub.
I still feel like I have been given keys to a Ferrari but am driving around like its a Vespa. My lack of imagination is the biggest hurdle.
Please let me know your thoughts on the below examples and if you know other ways I can set up automated workflows to give me an edge.
Getting better!!
Example: contact context agent. I organized & uploaded all my contacts (LinkedIn connections, ADW subs, personal contacts…all securely on my local machine). I am being reminded how everything fits together. Serendipity comes easier with great context. One concrete example is that this agent looked at an upcoming conference agenda, picked out a presenter who was first degree LinkedIn connection, but I really didn’t know that well. This person was also on my ADW distribution list. This gave me a chance to reach out prior with a thoughtful comment…we set up a meeting at the conference, which resulted in a partnership conversation that is getting started. I would have missed this entire chain of events.
Example: competitive intel agent. I created a list of companies that I want to keep track of. I first set up a full research report on each (found a great tool to use for this, and then spent quite a bit of time tuning the process, so this “agent” now does this work for me). Today the system sends me an email every weekend with all the most recent news, blogs, podcasts from each competitor, summarized for me, with the angle of how that commentary might specifically relate to SymetryML (red, yellow, green relevance). Any new company I come across, I just ask it to be added to this process, the full competitive intel report is created and the company is added to the weekly summary.
Example: publishing agent (more on this in coming weeks). I started a book many years ago and finally got it finished with Claude’s help. This was actually more time consuming than you might think.
Example: distribution agent. I will aways personally write the ADW. While I am sure an AI agent could do a version of this work for me, I learn by pulling this all together. Plus, I enjoy it.
The process is this: I send a Substack email Friday 7am ET, and do a single post on LinkedIn. I’ve set up a system such that, when the ADW email is sent, Flow OS breaks the ADW down and pulls together a series of related X (Twitter) posts. The goal is greater distribution. I have not yet automated this as I need to work to improve the social media posts Flow/Claude creates, but there will be a time when my newly established Alt Data Weekly X handle will have automated short summaries of the ADW. Open to ideas here…still fine tuning the output.
If you want to get in the Flow OS let me know. Perfect for small teams looking to make AI work for them. Happy to discuss and learn with you.